The Semantic Web
Written by Annette Devilee – prepared as part of the assessment for her Master of Learning Science and Technology (MLS&T) at The University of Sydney. 2008.
Introduction
Currently, our searches through that vast amount of data on the Internet are based on keywords. With the amount of data increasing all the time, it really is becoming unmanageable. Even the most technologically savvy people can’t always find what they want. We need some sort of powerful tool to support us. We need our machines to do more of the work for us.
At the moment there really is not enough metadata. Our computers can’t carry out our searches (process queries) if they can not understand what is in each document. The Semantic Web is a “huge engineering solution” (Palmer, 2001-09) to this problem. It is the architecture to make the web more like a global database.
The technical principles of the Semantic Web are straightforward. Firstly, the information on the Semantic Web needs to have machine readable references. Secondly, it must be capable of being interpreted on a global basis. This means that it can be created or searched by anyone who speaks any language and automated agents will do the work to find it and even translate it to our native language.
The Semantic Web is a Web that includes documents, or portions of documents, describing explicit relationships between things and containing semantic information intended for automated processing by our machines. (Berners-Lee, Connolly & Swick, W3C 1999)
Technologies for the Semantic Web
The Semantic Web needs to be built on some sort of data structure that will allow people to create it and machines to read it. This structure is built on the growing stack of W3C recommendations related to the Semantic Web (Web Ontology Working Group 2004): XML, XML Schema, RDF, RDF Schema and OWL. Each of these technologies is described below.
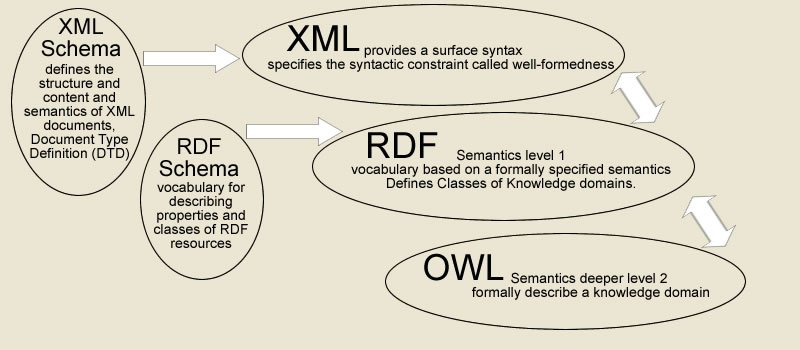
eXtensible Markup Language (XML)
XML is an ideal vehicle for the exchange of data, especially metadata. It “was created to structure, store and to send information” (Bray, 2001). Extensible refers to its ability to interchange information regardless of its application. While HTML focuses on the presentation structure of documents in the browser, XML (which looks similar) is a more generic data description vehicle. That data may in fact be the presentation structure of a document in a browser, commonly referred to as XHTML!
XML provides the surface syntax for structured documents. Syntactically well-formed XML contains a hierarchy of named elements and their attributes. It can be parsed by computer software and read by people trained in decoding it. By itself, XML places no semantic restriction on element or attribute names or their organisation. Meaning is conveyed by the XML if the person or software reading the XML is predisposed to comprehending it.
An XML schema [1] is a description for an application of XML. It embodies a set of rules about which named elements may be used and their hierarchical relationships, sequence, optionality and multiplicity. The schema describes the particular named attributes that elements may take on, and if required, a particular set of enumerated values for them. Schemas are themselves expressed as XML in one of several formats standardised by W3C.
An XML schema defines a language for a given application or knowledge domain. As long as both creator and reader are referencing the same schema (like a babel fish), then sense can be made of the XML. Included in the syntax of XML is the means to refer to a schema.
Resources Description Framework (RDF)
RDF is “a framework for describing and interchanging metadata” (Bray, 2001). Therefore, it is a meta-metadata XML, defined by a single global schema. It is “a general-purpose language for representing information in the Web” (Brickley & Guha, 2002).
The problem is that over the whole Web, resources have a huge range of purposes, formats and other attributes that characterise them. Beyond the basic aspects like name, creation date etc, there are few attributes that would apply to all resources. Therefore, a single metadata schema would have dozens, even hundreds of descriptors, most of which would be irrelevant to a particular resource.
Instead, RDF is a standardised top-level XML that can carry metadata and other elements that follow domain-specific schemata. It does this by qualifying its elements through namespace references to those external schemata.
RDF makes it possible to encode and interpret resources in a way so that any computer or software can access it, regardless of the vocabulary it uses. It is a data model for metadata that provides a syntax so that everyone can at least exchange and use it.
Metadata is about attributing resources by assigning values to properties. The mechanism for doing this with RDF (and to use W3C jargon) is to construct an RDF triple which consists of a subject (the resource), property and object (its value). For example, the triple for the statement “this page (subject) has the author (property) of Culley (object)” is (author, page, Culley), in that order.

This type of diagram is used by Tim Berners-Lee (1998).
This page (subject) has the title (property) “What is the technical basis for the Semantic Web?” (object). The triple (title, page, “What is the technical basis for the Semantic Web?”).

Activity 7.1 Create a similar diagram for the triplet (author, page, “S. Jones”)
This page has its own URI. The Author is represented by the URI for their home page. The Title is a “literal”. The RDF triplets are made up of URIs or literals / blank nodes
A document is built with RDF in the following way:
<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
.
. Description goes here
.
</rdf:RDF>Now let us add some properties:
<?xml version="1.0"?>
<RDF>
<Description about="http://lrnlab.edfac.usyd.edu.au/CoursesPG/edpc5021/edpc5021_2006_internal/
wk09/folder.2006-05-09.3497570531/TechnicalTheme1">
<author>Culley</author>
<homepage>http://lrnlab.edfac.usyd.edu.au/Members/Culley_Annete/index_html/document_view</homepage>
</Description>
</RDF>The example above is simplified. Namespaces are omitted.
Activity 7.2 Write a simplified RDF statment of the triplet (author, page, “S. Jones”). Use the above example as your template.
The full RDF XML for this might look something like:
<rdf:RDF xmlns:rdf=http://lrnlab.edfac.usyd.edu.au/CoursesPG/edpc5021/edpc5021_2006_internal/
wk08/folder.2006-05-02.7124458780/TechnicalTheme1 xmlns:dc=http://purl.org/dc/elements/1.1/
xmlns:foaf=http://lrnlab.edfac.usyd.edu.au/Members/Culley_Annete/index_html/document_view>
<rdf:Description rdf:about="">
<dc:creator rdf:parseType="Resource"><foaf:name>A.Culley</foaf:name></dc:creator>
<dc:title>What is the technical basis for the semantic web?</dc:title>
</rdf:Description>
</rdf:RDF>Extension Activity 7.3 This is an optional challenge. Write a full RDF XML statement for the triplet (author, page, “S. Jones”).
The Semantic Web will be built on top of this data.
RDF Schema is a vocabulary for describing properties and classes of RDF resources, with semantics for generalization-hierarchies of such properties and classes. Using RDF Schema, you can group terms into certain classes, and define what classes properties can be applied to, and take on (2004, Web Ontology Working Group).
Why do we need more than XML and RDF? “What these don’t provide is any Properties of their own. RDF doesn’t define Author or Title or Director or Business-Category” (Bray, 2001). This is why we need OWL.
Web Ontology Language (OWL)
OWL is a newly developed ontology language [2]. It “is a vocabulary extension of the Resource Description Framework (RDF). OWL adds more vocabulary for describing characteristics of properties and classes or relations between classes” (2004, Web Ontology Working Group). OWL provides the metadata vocabulary. It is used to describe the information and their relationships with other information on the web. Using OWL you can describe the knowledge domain and then use that specification to make assertions about what is in the domain.
Here is a simple example of OWL from the W3C. It is a simple (and incomplete) definition of three classes: Winery, Region, and ConsumableThing, each of which is given with a name:
RDF/XML Syntax: owl:Class
<owl:Class rdf:ID="Winery"/>
<owl:Class rdf:ID="Region"/>
<owl:Class rdf:ID="ConsumableThing"/> The next example from W3C defines a simple (and incomplete) definition for the class PotableLiquid that is a sub-class of ConsumableThing:
RDF/XML Syntax: rdfs:subClassOf
<owl:Class rdf:ID="PotableLiquid">
<rdfs:subClassOf rdf:resource="#ConsumableThing" />
</owl:Class>For more OWL Examples go here
Activity 7.4 Write RDF/XML syntax statements to define the 3 classes: Pet Shop, Suburb, Pet. Then define a Cat as the subclass of Pet.
Conclusion
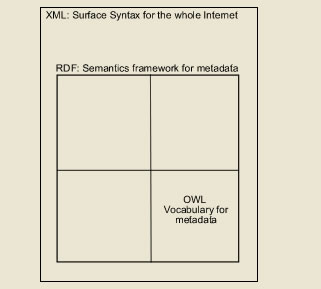
The three types of technology that we have explored can be viewed in this simplistic manner. XML provides the surface structure and the syntax so that it can be read by the entire web. RDF provides a standard means of referencing metadata. OWL provides the vocabulary for the metadata.
[2] An ontology language is a means by which one can formally describe a knowledge domain. Ontology is about describing objects and their relationships
[2] An ontology language is a means by which one can formally describe a knowledge domain. Ontology is about describing objects and their relationships
References
- Web Architecture: Describing and Exchanging Data W3C Note 7 June 1999. by Tim Berners-Lee, Dan Connolly& Ralph R. Swick, W3C
- Why RDF model is different from the XML model Tim Berners-Lee Date: September 1998.
- What Is RDF by Tim Bray January 24, 2001
- OWL Web Ontology Language Overview, W3C Recommendation 10 February 2004, Web Ontology Working Group
- The Semantic Web: An Introduction by Sean B. Palmer, 2001-09
- The Semantic Web, Taking Form by Sean B. Palmer,1999
- FOAF Vocabulary Specification Dan Brickley and Libby Miller 2000-2005
- XML Schema by C. M. Sperberg-McQueen and Henry Thompson Created April 2000
- XML Schema Definition Language: W3C XML Schema Working Group and Schema Specifications [Fall 1999] The co-chairs of the XML Schema Working Group are Dave Hollander (CommerceNet) and C. M. Sperberg-McQueen (W3C).
- Introduction to XML a tutorial on XML
- RDF Vocabulary Description Language 1.0: RDF Schema Brian McBride 2002
- Appendix B. OWL Examples in XML Syntax